{label}Menu
{contenu}
Standards
{contenu}
The standards provide uniform technical reading and support.
This is interesting if the technical framework and the training of developers is always the same.
But when the team is confronted with new demands, that involve changes in habits.
Too closely following the norms can be sort of jail that create a waste a lot of time.
This is interesting if the technical framework and the training of developers is always the same.
But when the team is confronted with new demands, that involve changes in habits.
Too closely following the norms can be sort of jail that create a waste a lot of time.
{contenu}
The main idea was to create a toolkit to save time by reuniting everything that was redundant in each project in a ready-to-use toolbox.
Not a too restrictive framework, but simple tools easily interlockable, and above all multilingual!
Indeed, at the time, the few tools offered did not support multilingual for both the interface and content!
For the modeling standard , "large variable ensembles":
The concept of "large" ensembles, i.e. when a group of "small" ensemble are brought together in a larger one so as to simplify representation and change the level of reflection.
Elements of the smallest level (small set (data object)) can be combined as a functional set:
- the interface, database engine, file system etc.... in short, functional sets dealing with the same small sets.
Example: the functional set "filesystem" manages small sets "file", "folder", "image sequence" etc...
And finally the big sets that group together the functional sets.
and if we take over the layout of the helpHPP, we can see the big sets:

The first helPHP prototype was made in 2001!
Many standards, now missing, were used, and therefore helPHP is not 100% compliant with a single standard, but can more or less comply with any.
The main idea was to create a toolkit to save time by reuniting everything that was redundant in each project in a ready-to-use toolbox.
Not a too restrictive framework, but simple tools easily interlockable, and above all multilingual!
Indeed, at the time, the few tools offered did not support multilingual for both the interface and content!
Even today, many tools are not designed for multilingual use, while the first criterion to differentiate one user from another is language!
Here we touch upon a first concept that leads to the first two standards that the development and organization of helpPHP is trying to follow:
For the modeling standard , "large variable ensembles":
It is an old forgotten norm of the 1990s (which is close to the UML), which was initially used, and whose principle is as follows: a data object may have a quantity of attributes or values which are unique to it and which form a "variable ensemble".
It can also be associated with another object, for example: the "User" object is associated with a "language" object -> "John" <->"English".
This means that the object "User Interface" will have to search in its translation dictionary, the "English" mentions to display.
This means that the object "User Interface" will have to search in its translation dictionary, the "English" mentions to display.
The representation of this relationship of "small variable ensembles" can be presented as in the following schemas (it looks like UML no?).
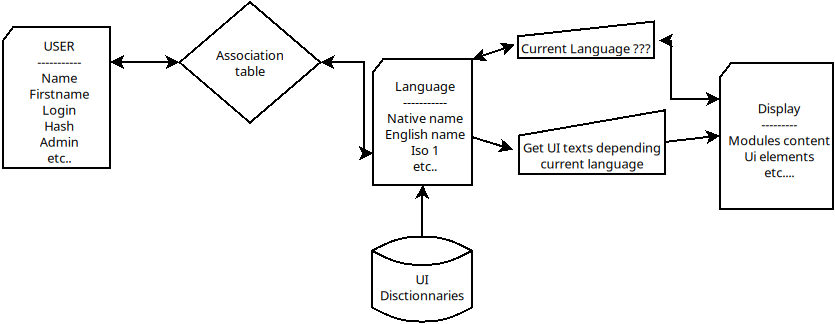
Note that today we speak more often of "data-object" in the various methods of modelling.
Note that today we speak more often of "data-object" in the various methods of modelling.
The concept of "large" ensembles, i.e. when a group of "small" ensemble are brought together in a larger one so as to simplify representation and change the level of reflection.
Elements of the smallest level (small set (data object)) can be combined as a functional set:
- the interface, database engine, file system etc.... in short, functional sets dealing with the same small sets.
Example: the functional set "filesystem" manages small sets "file", "folder", "image sequence" etc...
And finally the big sets that group together the functional sets.
and if we take over the layout of the helpHPP, we can see the big sets:
In this diagram, we have as a large set on the side of the main essentially:
- The libraries, each being a functional set manipulating one or more small sets of the same nature.
- The libraries, each being a functional set manipulating one or more small sets of the same nature.
- Modules.
On the side of the instance of large ensembles also of smaller size:
- Configuration data
On the side of the instance of large ensembles also of smaller size:
- Configuration data
- API
- back office (admin)
- the (public) front
- back office (admin)
- the (public) front
As far as utils are concerned, it is not an ensemble, because they have little in common.
There are many ways to represent this diagram, and the UML fits very well.
What's his point?
- At the level of the large sets: Determine the "relational" points between the sets. Each relational point is potentially a security problem, and/or data exchange format.
- At the functional set level: Bring together and therefore pool all that concerns the same type of data object, and optimize by limiting code redundancy.
- At the data-object level: consider higher levels and never make too much complicated object. And for that we will use the CRUD standard to treat them.
What's his point?
- At the level of the large sets: Determine the "relational" points between the sets. Each relational point is potentially a security problem, and/or data exchange format.
- At the functional set level: Bring together and therefore pool all that concerns the same type of data object, and optimize by limiting code redundancy.
- At the data-object level: consider higher levels and never make too much complicated object. And for that we will use the CRUD standard to treat them.
{contenu}
The CRUD Standard:
To understand what a data object is and how it will be handled during programming, let's take the example of an application to manage a car stock at a dealership:
A car is an object, having a model reference.
This car is associated with several other objects that can be used on several different models:
A car is an object, having a model reference.
This car is associated with several other objects that can be used on several different models:
- rim: size and type
- tire: tail and type etc...
- body paint: color, varnish etc...
- Engine: power, type, etc.
In short, every object including the car object needs to be manipulated according to four actions that form the CRUD standard: Create, Read, Update, Delete
Each action involves modifying the object (and the database where it is recorded).
And so the simplest functional module in helpPHP will apply its four actions to an object.
Yes, but how do I associate the car object with the tire object? Via an association object (and therefore an associative database table).
This will therefore create interfaces or are manipulated several objects associated with ...
Example I Create a new car, associated with various chosen objects:
- I create the new car object, and I get his ID after insertion
- I associate in the various association tables, the various objects chosen and I associate them with the id of the new car
The car object must be treated before its associations.
For this way of managing objects to be robust it takes two things:
1: Each object will have an ID assigned by the database, but in many cases you also have to give it a unique logical name, because ids can change.
2 : although the methods CRUD often seem the same writing, it is necessary to avoid attempting to use treatment templates.
This makes modifications, and extensions very complicated, but also most of the time, processing can no longer be put into OPcache, which is a big concern in terms of performance.
This makes modifications, and extensions very complicated, but also most of the time, processing can no longer be put into OPcache, which is a big concern in terms of performance.
{contenu}
helPHP has evolved a lot over time, like PHP and Javascript.
But before being proposed as an open source it has been completely rewritten following the PSR Standards for helpPHP and Ecma6 for Javascript as much as possible, but with some subtlety as we will see later on in the chapter on module creation, and also naming standards..
Other standards:
helPHP has evolved a lot over time, like PHP and Javascript.
But before being proposed as an open source it has been completely rewritten following the PSR Standards for helpPHP and Ecma6 for Javascript as much as possible, but with some subtlety as we will see later on in the chapter on module creation, and also naming standards..
Regarding the organization of files we will see this in the next chapter.
TitreRésumé
Which ones?
Date de création2025-11-17 00:00:00Date de publication2025-11-25 00:00:00

